
지난 포스팅에 이어서 트랜스포머의 디코더에 대해 알아보겠습니다
디코더의 구조를 보시면 인코더와 많이 닮아있습니다. 가장 큰 차이라면 멀티헤드 어텐션이 두 종류가 사용되었다는 것입니다
디코더 블럭에서는 셀프 어텐션으로 만들어진 마스크드 멀티헤드 어텐션(Masked Multi-head attention)과 인코더-디코더 어텐션으로 만들어진 멀티헤드 어텐션이 사용되었습니다. 오늘 포스팅의 두 주인공이 될 것입니다
디코더에서의 데이터의 흐름은 ⓵ 단어의 원래 임베딩 벡터 + 위치 임베딩 벡터가 합산되어 디코더 블럭에 입력되고 ⓶ 해당 입력이 Q, K, V로 변환되어 마스크드 멀티헤드 어텐션과 add&norm 층을 거친 후 ⓷ 쿼리 가중치가 곱해져 쿼리 벡터로서 인코더-디코더 어텐션으로 이루어진 멀티헤드 어텐션에 입력됩니다. 멀티헤드 어텐션에 입력되는 키와 밸류 벡터는 인코더 부분에서 넘어온 출력값에 키 가중치와 밸류 가중치를 곱해 만들어진 키 벡터와 밸류 벡터를 사용하게 됩니다. ⓸ 나머지는 인코더 부분과 동일하고 마지막에 소프트맥스 함수를 가지는 출력층에서 예측 단어 후보들에 대한 확률 값이 출력됩니다
그러면 디코더 블럭에 있는 두 멀티헤드 어텐션에 대해 알아보겠습니다
멀티헤드 어텐션(Multi-head attention)
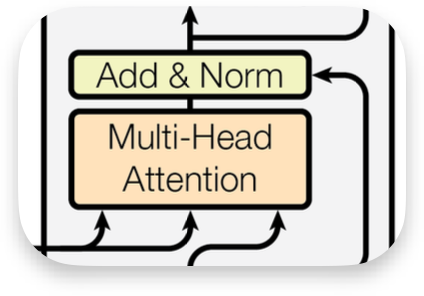
디코더 구조상 위쪽에 위치한 멀티헤드 어텐션에 대해 먼저 알아보겠습니다. 멀티헤드 어텐션은 여러개의 어텐션을 사용했다는 뜻이고 어떤 종류의 어텐션이 사용되었는지는 때마다 다릅니다. 인코더 블럭에 있는 멀티헤드 어텐션에서는 셀프 어텐션을 사용했고, 디코더 블럭에 있는 멀티헤드 어텐션에서는 인코더-디코더 어텐션을 사용했습니다
인코더-디코더 어텐션은 이미 1편에서 다루었습니다. 인코더에서 넘어온 은닉 상태 벡터의 정보와 디코더 블럭의 입력 벡터를 이용해 어텐션을 구하는 것입니다. 트랜스포머에서는 쿼리, 키, 밸류 벡터를 사용하는데, 이 때 키 벡터와 밸류 벡터는 인코더에서 넘어온 은닉 상태 벡터에 키 가중치와 밸류 가중치를 곱해 얻습니다. 반면 쿼리 벡터는 디코더가 입력받은 정보가 마스크드 멀티헤드 어텐션을 거친 후 내놓는 벡터에 쿼리 가중치를 곱해 얻게됩니다. 정리하자면, $$\begin{align} Q = h_{decoder} \cdot W_{Q} \\ K = h_{encoder} \cdot W_{K} \\ V = h_{encoder} \cdot W_{V} \end{align}$$
이렇게 얻은 쿼리, 키, 밸류 벡터를 이용해 $Attention(Q, K, V) = Softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V$ 연산을 수행하면 하나의 헤드에서의 연산이 완료되는 것이고 여러 헤드에서 나온 결과를 concat하여 add&norm 층으로 입력시키게 됩니다
마스크드 멀티헤드 어텐션(Masked Multi-head attention)
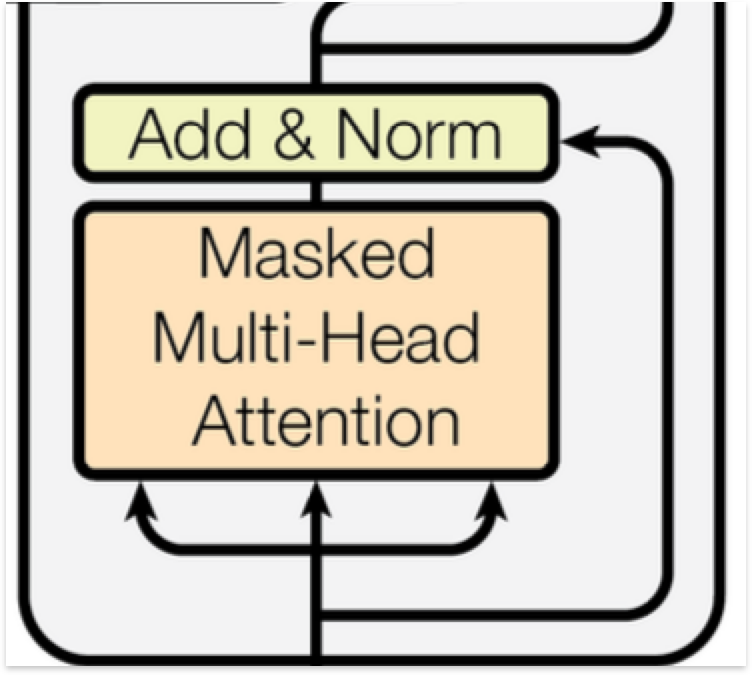
디코더 블럭의 마스크드 멀티헤드 어텐션은 인코더-디코더 어텐션이 아닌 셀프 어텐션입니다. 즉, 디코더가 입력 받는 단어 임베딩 벡터에 위치 임베딩 벡터를 더해준 벡터를 이용해 생성된 쿼리, 키, 밸류 벡터를 이용해 셀프 어텐션이 수행되는데 여기서 중요한 개념인 teacher forcing이라는 개념이 등장합니다.
Teacher forcing이라는 것은 학습과정에서 현재까지 예측한 단어들을 이용해 다음 단어를 예측하는 것이 아니라 단어 예측과는 별개로 정답 데이터 정보를 입력해주는 것을 말합니다. 모델은 한 단어를 예측한 뒤에 그 단어를 토대로 다음 단어를 예측하고 다시 그 단어를 통해 다음 단어를 예측하는 과정을 통해 전체 예측 문서를 만들어냅니다. 그렇기 때문에 각 스텝에서 올바르게 예측했는지가 다음 스텝의 예측에 큰 영향을 미치게 됩니다. 학습 과정중에는 당연히 예측을 틀릴 확률이 높기 때문에 정답 데이터를 넣어주며 "이렇게 해야지"하고 말해주는 것입니다.
Teacher forcing의 한 가지 문제점은 정답 데이터가 주어지기 때문에 어텐션 스코어를 구할 때 이후에 예측해야 할 단어들에 대해서도 어텐션 스코어를 구하고 그것이 예측에 활용이 될 수 있다는 것입니다. 따라서 어텐션 스코어를 구한 뒤에 현재 스텝에서 예측하려는 단어 이후에 오는 단어들의 어텐션 스코어를 가린 후 예측을 진행합니다. 가리는 것을 마스킹한다고 하기 때문에 마스크드 멀티헤드 어텐션이라는 이름이 붙었습니다.
I love you라는 문장에 대해 어텐션 스코어가 다음과 같이 구해졌다고 가정하겠습니다 (여기서 <SOS> 토큰은 start of sentence의 약자로 문장의 시작을 나타내는 토큰입니다)
| <SOS> | I | love | you | |
| <SOS> | 7 | 3 | 2 | 1 |
| I | 1 | 6 | 1 | 3 |
| love | 2 | 3 | 5 | 3 |
| you | 1 | 4 | 2 | 5 |
그러나 <SOS> 토큰은 자기 자신인 <SOS> 토큰 이후의 정보를 사용할 수 없고 I, love도 마찬가지로 자기 자신보다 위에 오는 단어에 대한 정보를 사용하면 안되므로 모두 $-\infty$로 치환해줍니다
| <SOS> | I | love | you | |
| <SOS> | 7 | $-\infty$ | $-\infty$ | $-\infty$ |
| I | 1 | 6 | $-\infty$ | $-\infty$ |
| love | 2 | 3 | 5 | $-\infty$ |
| you | 1 | 4 | 2 | 5 |
$-\infty$로 치환해주는 이유는 어텐션 스코어를 가중치로 변환시키기 위해 사용하는 소프트맥스 함수에서 이 $-\infty$가 0으로 바뀌기 때문입니다
'딥러닝 > 트랜스포머' 카테고리의 다른 글
| 트랜스포머 시리즈 4편 트랜스포머의 구조 - 인코더 (0) | 2024.02.05 |
|---|---|
| 트랜스포머 시리즈 3편 Q, K, V (0) | 2024.02.04 |
| 트랜스포머 시리즈 2편 Self-Attention 셀프 어텐션 (0) | 2024.02.02 |
| 트랜스포머 시리즈 1편 Attention 어텐션 (0) | 2024.02.01 |



