해당 포스팅은 William E. Shotts, Jr.의 오픈소스 저서 The Linux Command Line(링크)를 번역한 내용입니다

이번 강의에서는 커맨드 라인에서 아마 가장 멋진 기능에 대해 알아볼 것입니다. 바로 I/O 리디렉션(redirection)입니다. "I/O"는 input/output의 약자이고 이 기능을 이용하면 파일에 대한 명령의 입력과 출력을 리디렉션하거나 명령을 연결하여 강력한 명령 파이프라인(pipeline)을 만들 수 있습니다. 이 기능을 사용하기 위해서 다음과 같은 명령어들을 알아보겠습니다:
cat sort uniq grep wc head tail tee
표준 입력, 출력, 에러
우리가 지금까지 사용한 많은 프로그램들은 어떤 종류의 출력을 생성합니다. 이 출력은 주로 두 가지 타입으로 구성됩니다:
- 프로그램이 만들어내는 데이터
- 상태 혹은 에러 메시지
유닉스의 "모든 것은 파일이다"의 관점을 고수하자면,
또한 많은 프로그램은 기본적으로 키보드와 연결되어 있는 표준 입력(standard input)(또는 stdin)으로부터 입력을 받습니다.
I/O 리디렉션은 입력 위치와 출력 위치를 변경할 수 있도록 해줍니다. 일반적으로 출력은 화면으로 가고, 입력은 키보드로부터 받습니다. 그러나 I/O 리디렉션을 사용하면 그것을 바꿀 수 있습니다.
표준 출력 리디렉션
I/O 리디렉션은 표준 출력의 목적지를 바꿀 수 있습니다. 표준 출력의 목적지를 화면 대신 다른 파일로 바꾸고 싶다면 리디렉션 연산자
여기서 우리는 /usr/bin 디렉토리의 내용 목록을 ls-output.txt 파일로 전송했습니다. 리디렉션된 출력을 살펴보겠습니다:
좋습니다, 큰 텍스트파일이군요.
리디렉션 실험을 또 한 번 해보겠습니다. 이번엔 조금 꼬아보겠습니다. 디렉토리 이름을 존재하지 않는 디렉토리로 입력해보겠습니다:
에러 메시지를 받았군요. 존재하지 않는 디렉토리 /bin/usr를 입력했기 때문에 당연합니다. 그런데 왜 에러 메시지가 ls-output.txt에 저장되는 대신 화면에 출력이 되었을까요? 답은,
이제 파일에 아무것도 없네요! 이는 ">"을 이용해 출력을 리디렉션하면 목적 파일이 처음부서 새로 쓰여지기 때문입니다.
앞에 아무런 명령어 없이 리디렉션 연산자만 사용하면 기존 파일의 내용을 지우거나 새로운 파일을 생성합니다.
그러면 새로운 결과를 덮어쓰지 않고 기존 내용에 이어서 쓰려면 어떻게 해야할까요? 그건 ">>" 연산자를 사용하면 됩니다:
">>" 연산자는 출력이 파일에 추가되도록 해줍니다. 파일이 존재하지 않는다면 ">"를 사용한 것처럼 새로 만들어냅니다. 한 번 실험을 해보죠:
명령을 세 번 반복했더니 세 배 큰 파일이 만들어졌습니다.
표준 에러 리디렉션
표준 에러 리디렉션은 전용 연산자가 없어 편의성이 조금 떨어집니다. 표준 에러의 리디렉션을 위해서는 파일 디스크립터(file descriptor)를 명시해주어야합니다. 프로그램은 여러 개의 번호가 매겨진 파일 스트림을 통해 출력을 생성할 수 있습니다. 이 파일 스트림의 첫 세 개를 표준 입력, 출력, 에러라고 하고 쉘은 이들을 내부적으로 파일 디스크립터 0, 1, 2로 참조합니다. 쉘은 파일 디스크립터 번호로 파일을 리디렉션 할 수 있도록 해줍니다. 표준 에러는 파일 디스크립터 번호 2번 이므로 다음과 같이 표준 에러를 리다이렉트 할 수 있습니다:

파일 디스크립터 "2"가 리디렉션 연산자 바로 앞에 놓이면 ls-error.txt로의 표준 에러 리디렉션이 일어납니다.
표준 출력과 표준 입력을 하나의 파일에 리디렉션
명령의 모든 출력을 하나의 파일에 담고 싶은 경우가 있습니다. 이를 위해 우리는 표준 출력과 표준 에러를 동시에 리다이렉트 해야합니다. 동시에 리다이렉트 하는 것은 두 가지 방법이 있습니다. 다음은 구 버전 쉘에서 동작하는 전통적인 방법입니다.

이 방법을 사용하면 두 개의 리디렉션이 일어납니다. 먼저 표준 출력을 ls-output.txt로 리다이렉트 하고, 그 다음으로 2>&1 표기를 통해 파일 디스크립터 2(표준 에러)를 파일 디스크립터 1(표준 출력)로 리다이렉트 합니다.
리디렉션의 순서가 중요함을 알아두세요. 표준 에러의 리디렉션은 항상 표준 출력 리디렉션 뒤에 일어나야합니다. 그렇지 않으면 동작하지 않습니다. 다음 예시는 표준 에러를 ls-output.txt 파일로 리다이렉트 합니다:>ls-output.txt 2>&1
그러나 다음 명령은 동작하지 않습니다:2>&1 >ls-output.txt
최신 버전의

위 예시에서는

원치 않는 출력 처리
때로는 '침묵이 금'일 때가 있는데, 명령의 출력을 원하지 않고 그냥 버리고 싶을 때가 있습니다. 특히 에러 메시지와 상태 메시지가 이에 해당합니다. 이를 위해서 시스템은 특수한 파일인 "/dev/null"에 출력을 리다이렉트합니다. 이 파일은 빗버킷(bit bucket)이라고 불리며 입력을 받고 아무것도 하지 않는 시스템 장치 입니다. 명령에 대한 에러 메시지를 감추고 싶을 때 다음과 같이 입력합니다:

유닉스 문화에서의 /dev/null
빗버킷은 고대 유닉스 개념으로, 그 보편성 때문에 유닉스 문화의 많은 부분에서 등장했습니다. 누군가 당신의 의견을로 보냈다고 말한다면... 무슨 뜻인지 아시겠죠? 더 많은 예시를 보고 싶다면 여기를 방문하세요 /dev/null
표준 입력 리디렉션
아직까지 표준 입력을 사용하는 명령어에 대해 만나보지 못했습니다(사실 만나긴 했는데 이 서프라이즈는 잠시 후에 공개하겠습니다). 그러니 이제 하나를 배워보겠습니다.
cat

대부분의 상황에서

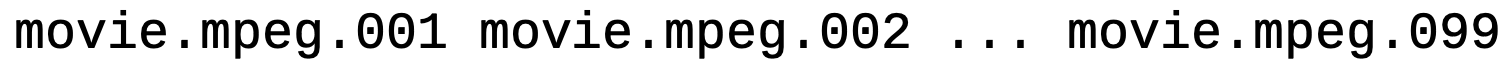
다시 이 파일들을 하나로 합치기 위해 아래 명령을 입력할 수 있습니다:

와일드카드는 항상 정렬된 상태로 결과를 반환하기 때문에 인자들이 알맞는 순서로 배열될 것입니다.
모든 것이 순조롭습니다. 하지만 이것이 표준 입력과 어떤 상관이 있을까요? 아직은 없습니다. 그러니 이제 다른 것을 시도해보죠. 만약

아무 것도 하지 않는 것처럼 보입니다. 하지만 사실은 해야할 일을 완벽하게 수행하고 있습니다.

다음으로

파일명 인자가 주어지지 않았을 때

명령을 입력한 뒤에 우리가 파일에 저장하고자 하는 텍스트를 입력합니다. 마지막에


다음으로 넘어가기 전에
파이프라인
명령어들이 표준 입력으로부터 데이터를 읽고 표준 출력으로 전송하는 것이 가능한 것은 파이프라인(pipelines)이라는 쉘의 기능 덕분입니다. 파이프 연산자

이것을 완전하게 실행하기 위해서 몇 가지 명령어들이 필요합니다. 이전에 표준 입력을 사용하는 명령어를 이미 한 번 만나보았다는 이야기를 기억하시나요? 그것은 바로

굉장히 편리한 기능입니다! 이 테크닉을 활용하면 표준 출력을 생성하는 모든 명령어의 출력을 아주 쉽게 볼 수 있습니다.
와 > 의 차이 |
처음엔 리디렉션 연산자와 파이프라인 연산자 > 의 리디렉션에 어떤 차이가 있는지 알기 어렵습니다. 쉽게 말해서, 리디렉션 연산자 | 는 명령어와 파일을 연결하고, 파이프라인 연산자 > 는 명령어의 출력을 다음 명령어와 연결합니다. | command1 > file1 command1 | command2
많은 사람들이 파이프라인을 배우는 과정에서를 시도하면서 "무슨 결과가 나올까?" 궁금해합니다 command1 > command2
정답: 아주 안좋은 일이 일어날 수 있습니다.
여기 리눅스 기반의 서버 설비를 관리하던 독자의 실제 사례를 보겠습니다. 슈퍼유저 권한에서 그는 다음과 같은 명령을 실행했습니다:# cd /usr/bin # ls > less
첫 번째 명령은 대부분의 프로그램이 저장된 디렉토리로 작업 디렉토리를 옮기고, 두 번째 명령은 쉘에게 파일를 less 명령어의 출력으로 덮어쓰라고 지시합니다. ls 디렉토리에는 이미 /usr/bin 프로그램 파일이 있었기 때문에 두 번째 명령어는 less 프로그램 파일을 less 의 출력으로 덮어썼고 ls 는 망가져버렸습니다. less
여기서 얻을 수 있는 교훈은 리디렉션 연산자는 조용히 파일을 생성하거나 기존 파일을 덮어쓰기 때문에 사용에 신중을 기해야 한다는 것입니다.
필터
파이프라인은 데이터에 복잡한 조작을 할 때 종종 사용됩니다. 여러 개의 명령어를 파이프라인에 넣는 것도 가능합니다. 이렇게 사용하는 명령을 필터(filters)라고 부릅니다. 필터는 입력을 받아 변환을 한 뒤에 출력합니다. 처음 사용해볼 것은

두 개의 디렉토리(
uniq

이 예시에서

wc

이 경우는

grep

프로그램 리스트에서
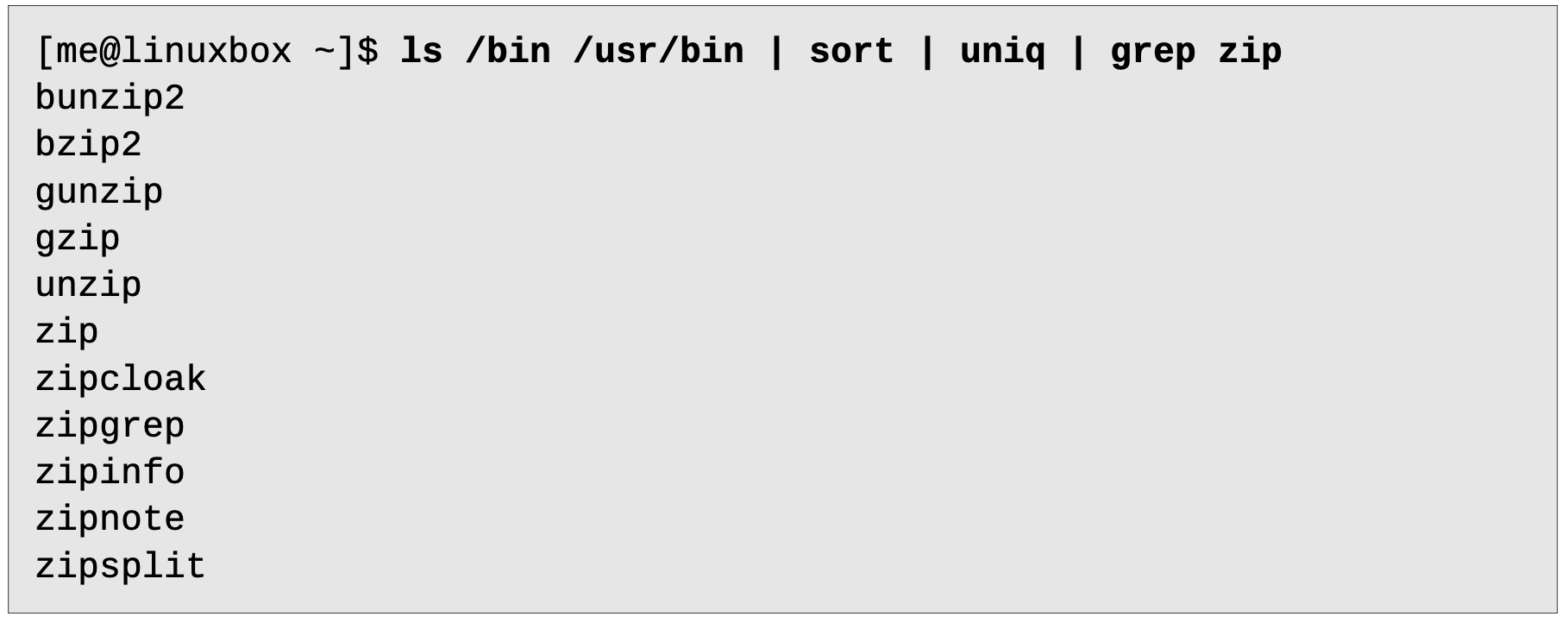
-i grep -v grep
head / tail
어떤 경우에 우리는 명령의 출력된 결과가 모두 필요하지 않을 수 있습니다. 첫 몇 줄이나 마지막 몇 줄만 필요할 수도 있죠.
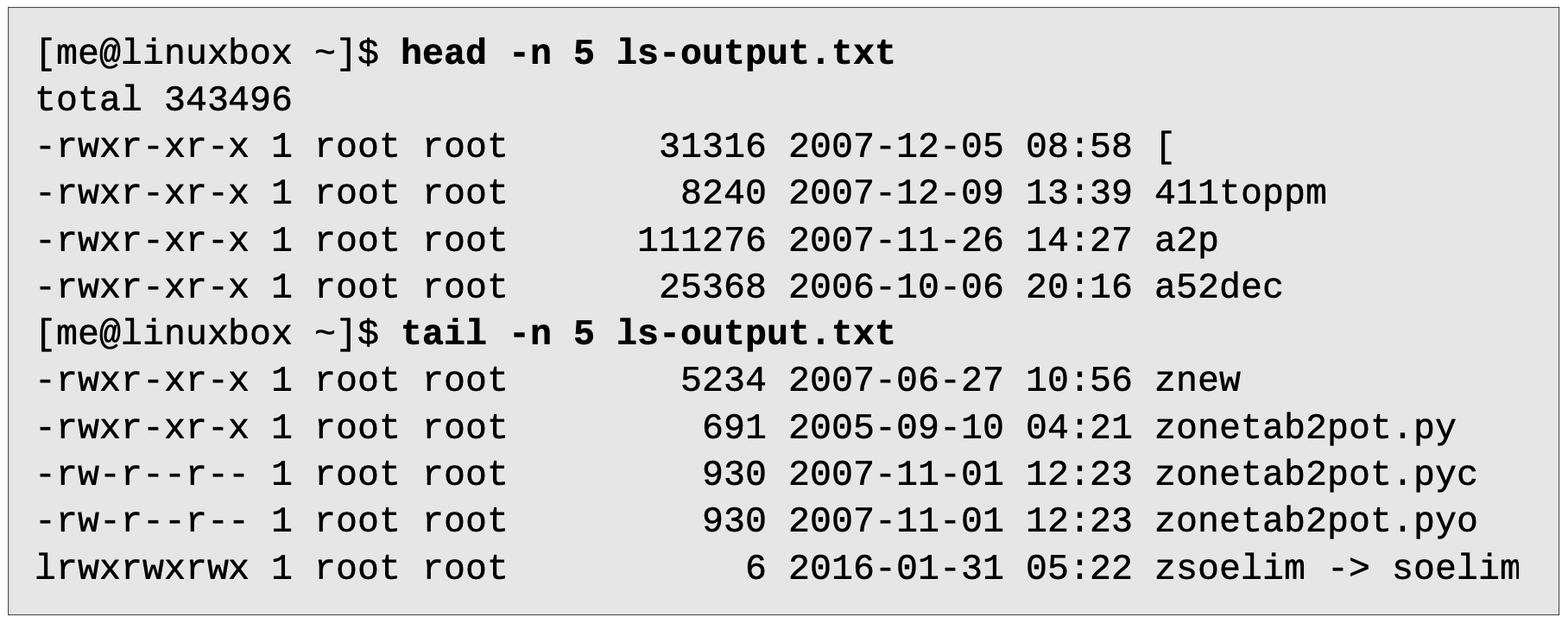
파이프라인에도 이 명령어들을 추가할 수 있습니다:

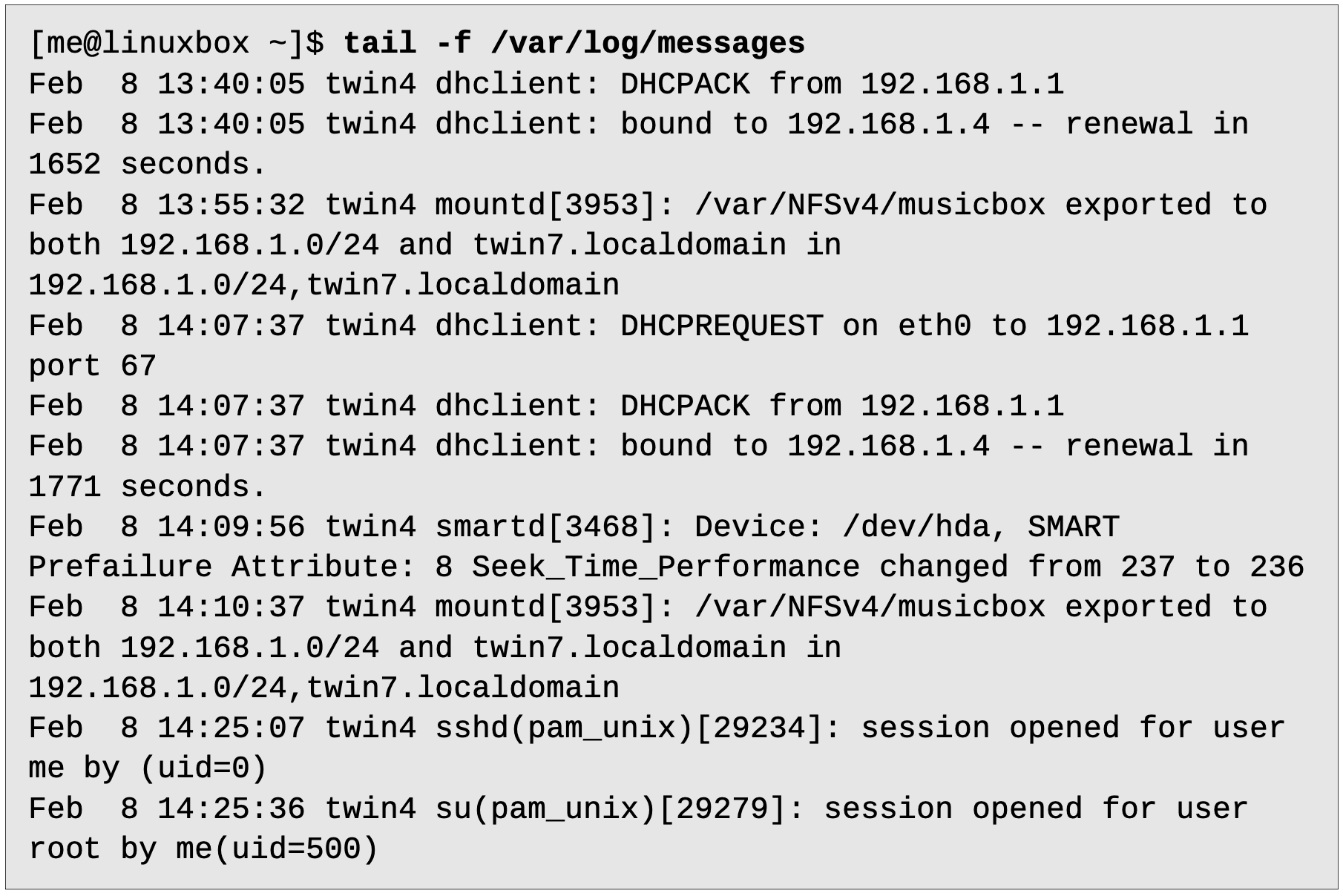
"
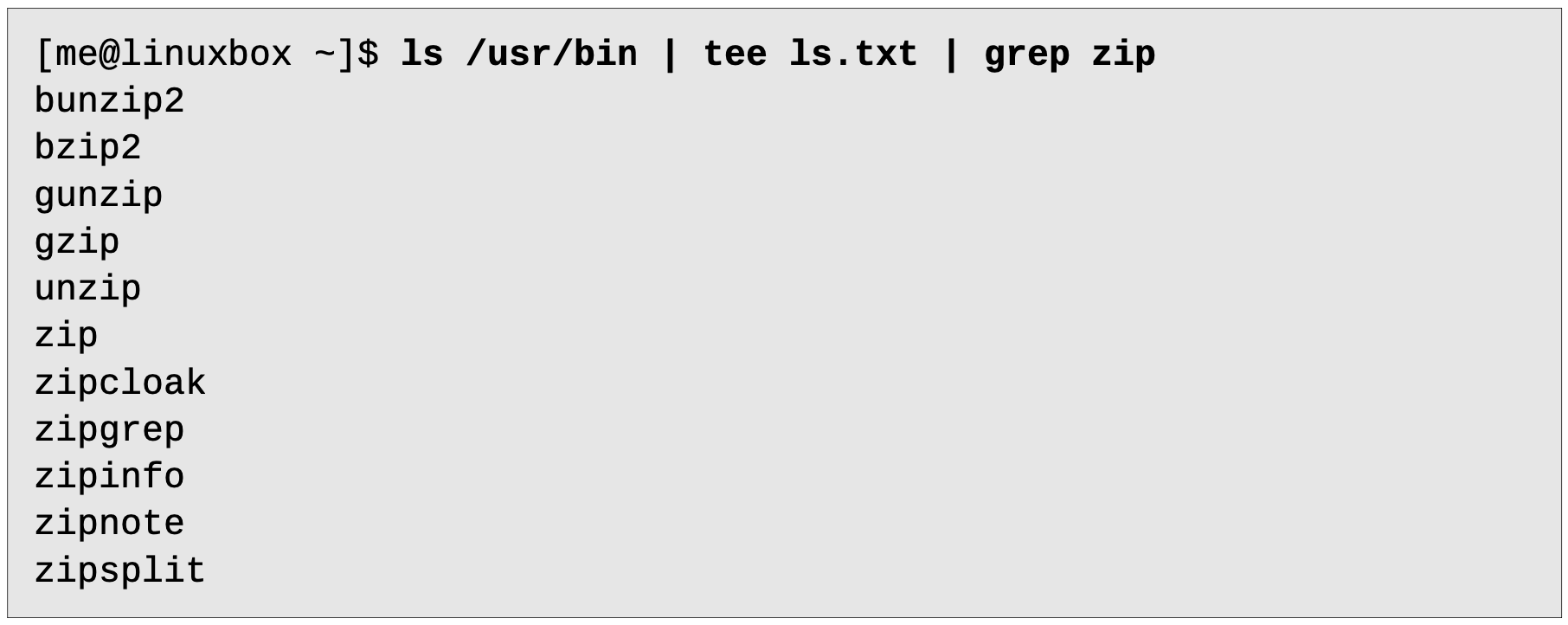
tee
배관 비유를 계속 사용하여 설명하자면,
요약
전과 마찬가지로 이번장에서 다룬 명령어들의 문서를 읽어보세요. 우리가 본 것은 이 명령어들의 가장 간단한 사용 예시들일 뿐입니다. 각 명령어는 여러개의 흥미로운 옵션들이 있습니다. 리눅스 경험이 쌓일수록 커맨드 라인의 리디렉션 기능이 특수한 문제를 해결하기 위해 매우 유용하다는 것을 알게될 것입니다. 이 밖에도 표준 입력과 출력을 사용하는 명령어가 많고, 대부분의 커맨드 라인 프로그램들은 중요한 메시지를 출력하기 위해 표준 에러를 사용합니다.
리눅스는 상상력이다
윈도우 운영체제와 리눅스 운영체제의 차이점을 설명해달라는 요청을 받으면 저는 종종 장난감에 비유하여 설명합니다.
윈도우는 게임보이와 같습니다. 당신은 게임 스토어에 가서 박스에 들어있는 새 제품을 구입합니다. 당신은 집에 와서, 전원을 키고, 그것을 가지고 놉니다. 예쁜 그래픽, 귀여운 음향효과도 나오죠. 그러나 얼마 지나면 함께 구매한 게임에 질리게 되고 다시 게임 스토어로 가서 점원에게 "이런 게임을 사고 싶어요!"라고 말하지만 수요가 없기 때문에 그런 게임은 존재하지 않는다는 대답을 듣게됩니다. 그러면 당신은 "하지만 이것 딱 하나만 바꾸면 된다구요!"라고 합니다. 점원은 그것은 불가능하다고 합니다. 게임은 카트리지 안에 봉인되어있습니다. 당신은 당신의 즐길 수 있는 게임이 다른 사람들이 결정해놓은 게임들에 국한된다는 것을 깨닫게 됩니다.
반면 리눅스는 세계 최대 규모의 건설 세트와 같습니다. 상자를 열면 그저 커다란 파츠 컬렉션을 마주하게됩니다. 무엇을 지으면 좋을지에 대한 제안과 함께 철근, 나사, 기어, 도르레, 모터가 잔뜩있습니다. 그래서 당신은 그걸 가지고 놀기 시작하죠. 제안에 있는 것을 하나 만들어보고 또 다른 것도 만들어봅니다. 얼마 지나면 뭘 만들지 스스로 아이디어가 떠오르게 됩니다. 이미 모든 부품이 있기 때문에 장난감 가게에 돌아갈 필요도 없습니다. 건설 세트는 당신이 원하는대로 당신의 상상을 실현합니다.
물론 선택은 당신의 몫입니다. 어떤 장난감이 당신에게 더 맞나요?
'리눅스 > Part 1 - Learning The Shell' 카테고리의 다른 글
| 리눅스 기초 | 8. 고급 키보드 트릭 (0) | 2024.05.28 |
|---|---|
| 리눅스 기초 | 7. 쉘처럼 세상 바라보기 (0) | 2024.05.24 |
| 리눅스 기초 | 5. 명령어 알아보기 (0) | 2024.05.22 |
| 리눅스 기초 | 4-2. 파일과 디렉토리 조작하기 (0) | 2024.05.21 |
| 리눅스 기초 | 4-1. 파일과 디렉토리 조작하기 (0) | 2024.05.20 |



