책과 논문은 과학적 지식을 나누고 담아두는 주요한 매체입니다. 때문에 우리는 어떤 분야의 최근 동향을 알고 싶을 때에 책과 논문을 찾아봅니다. 최근에는 이런 매체에서 지식 정보를 더 잘 추출하기 위한 툴을 개발하는 것에 관심이 커지고 있습니다. 물론 지금도 이런 일들을 해주는 툴들이 존재 하지만 한계점들이 있습니다:
- 파서(parser, 문서에서 정보를 추출하는 툴이나 알고리즘)는 텍스트나 이미지 혹은 도표를 있는 그대로 가져옵니다. 파서가 가져온 raw 데이터는 그것이 저자에 대한 정보인지, 논문의 제목인지, abstract인지에 대한 정보를 가지고 있지 못합니다. 즉, 책이나 논문의 구조에 대한 이해 없이 정보를 긁어온다는 것입니다.
- 또한 파서가 가져온 데이터는 문장, 단락, 담화 단위의 구성 뿐만 아니라 문서의 내용에 대한 이해가 없습니다.
이러한 한계 때문에 다운스트림 모델들을 이용해 한계를 극복합니다. 이 모델은 파서가 가져온 토큰들을 이용해 책이나 논문 자체의 구조, 텍스트의 구조, 텍스트의 의미를 얻습니다. 그러나 많은 경우 다운스트림 모델들이 프로토타입 수준이기 때문에 특정 한가지 작업만 수행할 수 있어서 여러 모델을 묶어 하나의 파이프라인으로 만들어줘야하는 번거로움이 있습니다.
그래서 저자는 papermage라는 과학 문서의 가공을 위한 오픈소스 툴킷을 만들었습니다. papermage는 과학 문서를 쉽게 다루게 해주는 도구와 기능 세트를 제공합니다. papermage에는 전반적인 기능을 도와주는 여러 파트가 있습니다. 지금은 이름만 언급하는 정도로 넘어가고 뒤에 자세하게 설명하겠습니다:
- megelib: 텍스트와 시각적 요소가 모두 포함된 문서를 처리하는 방법을 제공해주는 라이브러리
- predictors: 다양한 SOTA 문서 분석 모델들을 통합합니다. 즉, 각 분석 모델들이 다른 프레임워크나 다른 방식으로 작동되더라도 원활하게 통합되어 함께 사용될 수 있습니다
- Recipes: (테스트 결과 잘 작동하는) 개별 모듈들의 조합을 제공하여 사용자들이 쉽게 과학 문서에 대해 multimodal 작업을 수행할 수 있게 해줍니다
물론 이전에도 이런 기능을 가진 소프트웨어는 있었습니다. 예를들어, GRO-BID, CERMINE, ParsCit과 같은 소프트웨어들이 있습니다. 그런데 이런 소프트웨어들은 여러개의 모델을 엮어놓은 형태이고 그렇기 때문에 새로운 모델이 나왔을 때 그 모델을 소프트 웨어에 추가하려면 파이프라인을 다시 짜거나 기존 모델들과 새로운 모델을 엮어주는 코드를 짜 줄 필요가 있는 등 통합에 어려움이 있습니다.
앞서 언급한 소프트웨어들은 CRF나 BiLSTM 기반 모델을 사용하는데 요새는 layout-infused Transformers 기반 모델과 CNN 기반 모델을 사용해서 문서의 텍스트와 구조적인 분석을 수행합니다. 마찬가지로 이들을 하나의 파이프라인으로 만들려면 이들을 엮는 코드를 작성하거나 따로 소프트웨어를 사용해야합니다.
papermage는 이런 부분들을 멋지게 해결한 소프트웨어입니다. 그럼 paperamge의 구성을 살펴보겠습니다.
Design of papermage
1. magelib
magelib은 문서를 직관적으로 표현하고 조작하기 위한 라이브러리 입니다. magelib은 문서를 인스턴스화 하기 위해 Parsers와 Rasterizer을 사용합니다. Parsers는 텍스트를 긁어오고 Rasterizer는 문서를 이미지화 해서 시각적인 구조 정보를 얻기 위해 사용됩니다. magelib은 세 가지 데이터 클래스를 제공합니다: Document, Layers, Entities. 먼저, Document는 텍스트를 기호로서 저장해둡니다. 즉, 페이지, 블록, 줄 같이 시각적으로 구분되는 단위들, 제목, abstract, 이미지, 표와 같이 논리적으로 구분되는 구조들, 그리고 문단, 문장, 토큰 처럼 의미적으로 구분되는 단위들을 고려하지 않고 저장한다는 의미입니다.
magelib의 Layers는 Document에서 부족했던 구조적인 구분을 Document의 attribute로서 가능하게 해줍니다. 예를 들어, doc.sentences, doc.figures, doc.tokens 처럼요. 아래 그림의 각 레이어를 보시면 이해가 되실겁니다.
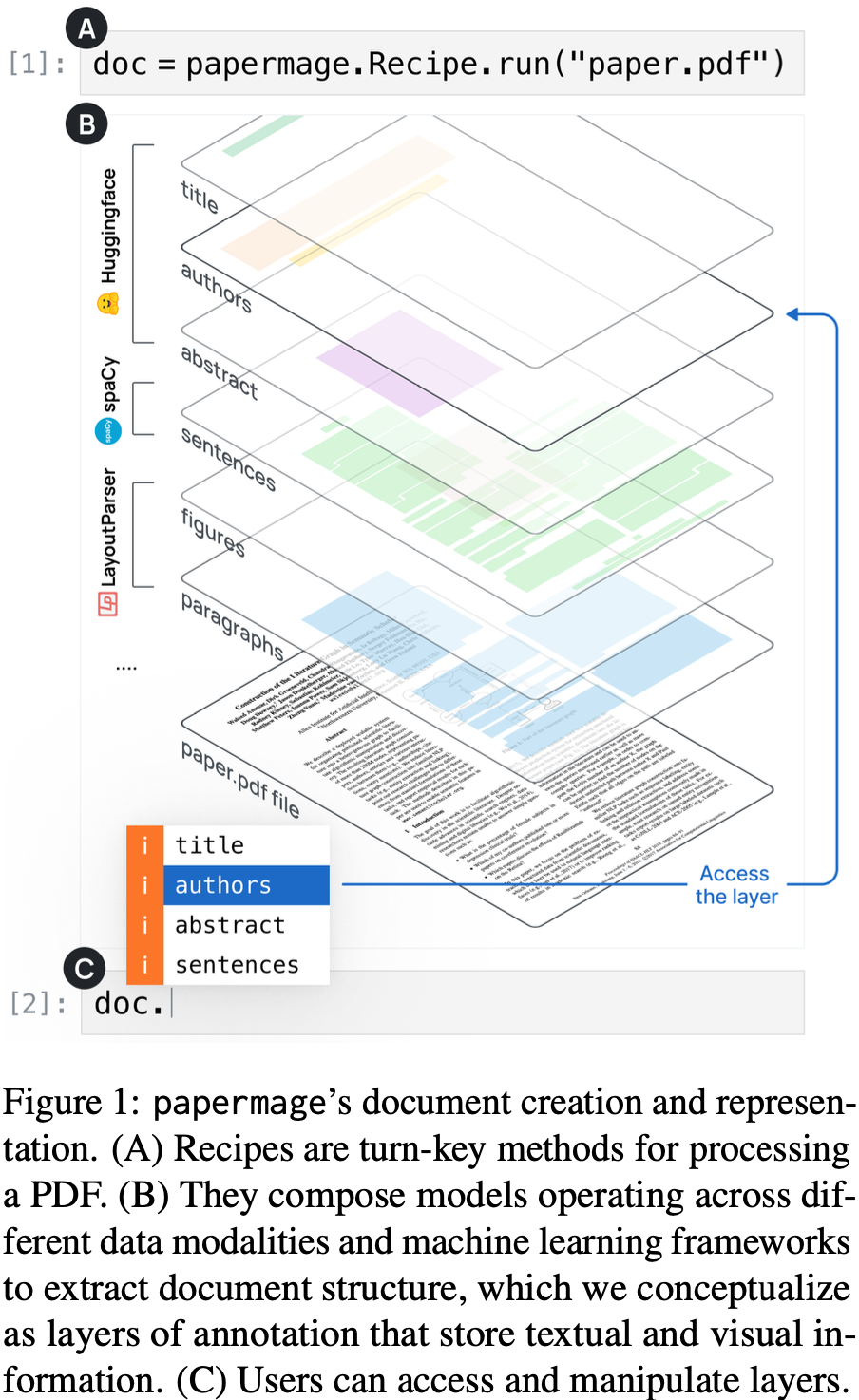
Layers는 다시 여러개의 Entities로 구성되어 있습니다. Entities는 Layer의 id (몇 번째 sentence, paragraph, token, ... 인지), span (text의 시작과 끝 위치), boxes (바운딩 박스에 대한 정보), text (가져온 문자열) 등의 정보를 제공합니다. 마찬가지로, Entities도 Layers의 attribute로서 불러올 수 있습니다. 예를 들어, doc.paragraphs[10].spans 처럼요. (아래 그림을 참고하세요)

또한 아래와 같이 텍스트를 편집할수도 있고
doc.paragraph[10].text = "testing editing text"
doc.paragraph[10].text
>>> testing editing text
각 레이어를 순회할 수도 있습니다
for paragraph in doc.paragraphs:
for sentence in paragraph.sentences:
for token in sentence.tokens:
...
아니면 시각적인 단위인 box를 통해서도 접근할 수 있습니다. 아래 이미지에 각 부분에 접근하는 방식이 잘 정리되어 있습니다.

2. Predictors
앞에서 우리는 각 Layers가 여러개의 Entities로 구성된다는 것을 알게 되었습니다. 그렇다면 애초에 Entities는 어떻게 구분이 되는걸까요? 문서의 멀티모달(vision, text) 구조를 분석하기 위해서 일반적으로는 CV 모델과 NLP 모델 여러개를 엮어 복잡한 파이프라인을 구성하게 될 것입니다. papermage는 Predictors라는 통합 인터페이스를 제공함으로써 문서와 맞는 Entities를 생성할 수 있도록 해줍니다. 즉, Box를 인식해주는 Box predictor, span을 인식해주는 span predictor 등이 따로 존재합니다.
Predictors는 SOTA 모델들을 이용해 문서내의 구조를 이해합니다. magelib과의 차이점은, magelib은 어느 문서에나 적용가능한 일반적인 툴이라면, Predictors는 과학 문서에 특화되어있다는 점입니다. Predictors는 (1) 다양한 기계학습 프레임워크의 모델과 호환되도록 설계되었으며, (2)텍스트 전용, 비전 전용, 멀티모달 모델을 통한 추론을 지원하고, (3) 기존 모델과 새로운 모델을 모두 지원합니다. 유저는 각 predictor에 어떤 모델을 적용할지를 정할 수 있고 파라미터와 하이퍼파라미터 조정을 할 수 있다고 합니다.
정리하자면 Predictors는 문서를 구조적으로 분석해서 들고오는 역할을 하고, magelib은 Predictors가 들고 온 정보를 쉽게 조회할 수 있도록 해주는 툴입니다.
3. Recipes
Recipes는 Predictors를 엮어놓은 조합들입니다. 앞에서 각 entity에 맞게 predictor를 따로 조정할 수 있다고 했었죠? 제작자들이 가장 좋은 퀄리티를 뽑아준다고 생각하는 조합을 만들어 놓은 것들이 Recipes라고 생각하면 됩니다. 요리사마다 자신이 생각하는 최고의 재료와 조리법 조합을 적어놓은 레시피와 똑같습니다.
결론
papermage는 과학 문서에 전문화된 파싱툴로서 CV, NLP 모델 이용하여 구조적인 이해를 바탕으로 문서의 각 부분을 구분하여 불러올 수 있도록 해주는 라이브러리 입니다. 오픈소스이기 때문에 ChatPDF나 SciSpace 같은 PDF와 QA를 할 수 있는 서비스를 직접 만들어보는 것도 가능하겠네요. 이상 오늘의 포스팅을 마치겠습니다.



