요약: transformer 기반의 시계열 예측 모델 PatchTST를 개발했다. PatchTST는 두 가지 특징을 가진다: 1. Channel-independence; 2. Patching. Channel-independence라는 것은 다변량 시계열 데이터(multivariate time series)의 각 채널을 분리하여 여러개의 단변량 시계열 데이터(univariate time series)로 만들어 독립적으로 처리하는 것을 의미한다. Patching은 하나의 긴 시계열에서 연속된 time step들을 한 단위로 묶어 토큰화 하는 것을 말한다.
1. 서문
트랜스포머 기반의 모델들은 자연어처리분야와 컴퓨터비전 분야에서 두루 활용되는 방법입니다. 그러나 시계열 데이터 예측에서만큼은 MLP 기반 모델들(N-BEATS, N-HiTS)이 더 뛰어난 성능을 보여주었습니다. 이 논문은 트랜스포머 기반의 모델(PatchTST, Patch Time Series Transformer)을 통해 시계열 데이터 예측을 수행하고자 합니다.
2. PatchTST 모델
PatchTST 모델은 시계열 데이터 분석을 위한 두 가지 특징을 가지고 있습니다. 첫 번째는 channel-independence이고, 두 번째는 patching 입니다.
2.1 Channel-Independence

Channel-independence는 다채널 시계열 데이터에서 각 채널을 분리하여 분석하겠다는 개념입니다. 예를 들어, 기상예측을 위해서는 다양한 변수(=채널)들을 고려해야합니다: 수온, 기온, 풍속, 습도 등, 각 채널을 분리하여 분석한 뒤에 예측을 수행한다는 것입니다.
이와 비교되는 개념은 channel-mixing이라는 개념입니다. Channel-mixing은 여러 채널을 혼합해 채널들 간의 복잡한 관계를 학습할 수 있다는 장점이 있습니다. (이 논문에서는 attention 메커니즘을 통한 channel-mixing과 비교하고있습니다.) 이와 반대로 channel-independent 모델은 여러 종류의 채널들이 동일한 모델을 통과하며 weight 값들을 공유하므로 직관적으로 생각했을 때에는 채널들 간의 상호작용을 포착하기 어려울 것 같습니다. 그러나 결과적으로는 channel-independent 모델이 channel-mixing보다 나은 성능을 보여주었다고 합니다. (하단 이미지 참고)

2.1.1 Channel-independence에 대한 분석
저자들은 channel-independent model의 성능에 대한 세 가지 측면에서 분석을 내놓았습니다:
- 유연성: 각 채널이 독립적으로 transformer layer를 통과하므로 자신만의 attention map을 가지게 되고, attention map을 통해 여러 패턴을 학습할 수 있기 때문에 다양한 데이터셋에 유연하게 대응할 수 있습니다.
- 데이터 의존성: channel-mixing 모델은 채널간 관계를 더 잘 학습할 수 있다는 장점이 있으나 대량의 데이터가 필요합니다. 그러나 channel-independent 모델은 데이터가 적은 경우에 더 효율적입니다.
- 오버피팅: channel-mixing 모델이 초반 몇 번의 epoch 후에 오버피팅이 일어나는 반면 channel-independent 모델은 오버피팅이 일어나지 않고 오랫동안 optimizing이 진행되었습니다. 그에 따라 예측 성능도 channel-independent 모델이 더 높았다고 합니다.
2.2 Patching

Patching은 인접한 데이터들을 묶어 하나의 단위로 만드는 것을 말합니다. 예를 들어, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]이라는 데이터를 patch length 2, stride 2로 patching하면 [1, 2], [3, 4], [5, 6], [7, 8], [9, 10]으로 나눕니다. 논문에서는 patching을 함으로써 input token의 개수를 줄여 시간적, 공간적 복잡도를 낮출 수 있고 그렇게 되면 더 긴 시계열 데이터를 학습시킬 수 있기 때문에 더 나은 forecasting 결과를 얻을 수 있다고 말합니다.
각 채널이 분리되고 patching된 이후에는 transformer encoder를 통과하게 됩니다. 이 논문에서는 vanilla transformer 모델을 사용했습니다. transformer encoder에서 나온 output은 다시 linear layer를 통과하며 prediction을 내놓게 됩니다. 여기까지가 기본적인 프로세스입니다. 저자들은 여기에서 더 나아가 self-supervised representation learning을 통해 성능을 더 향상시키기 위한 시도를 했습니다.
3. Self-Supervised Representation Learning

Self-supervised representation learning은 라벨링 되어있지 않은 데이터에서 의미있는 정보를 추출하기 위한 기법입니다. Supervised learning에서는 patch들이 온전하게 transformer encoder와 linear layer를 통과한 이후 prediction을 내놓지만, self-supervised learning에서는 patch 중 일부가 랜덤하게 마스킹되어 모델을 통과하면 출력으로 마스킹 된 patch를 내놓는 작업을 수행하게 됩니다. (출력이 다르기 때문에 마지막 layer는 다른 layer를 사용합니다.) 여기서 마스킹된 patch와 인접한 patch들이 마스킹 된 patch의 정보를 가지고 있으면 학습이 제대로 되지 못하므로 서로 overlap되지 않게 설계합니다. (즉, patch lengh = stride가 되게 설계합니다)
이 과정을 통해 학습된 모델은 한 채널 내에서 일어나는 패턴과 관계를 더 깊이 이해할 수 있게 되고 그에 따라서 모델은 더 일반화된 표현력을 가지게 됩니다. Self-supervised learning로 pre-trained 된 모델은 transfer learning에 사용됩니다.
4. Experiment Results

4.1 Representation learning
실험은 PatchTST(/patch size)와 다른 transforemer-based model들과 시계열 예측 성능을 비교한 것이다. 평가 지표로는 Mean Squared Error와 Mean Absolute Error를 사용했다.
4.1.1 Supervised learning

4.1.2 Self-Supervised Learning
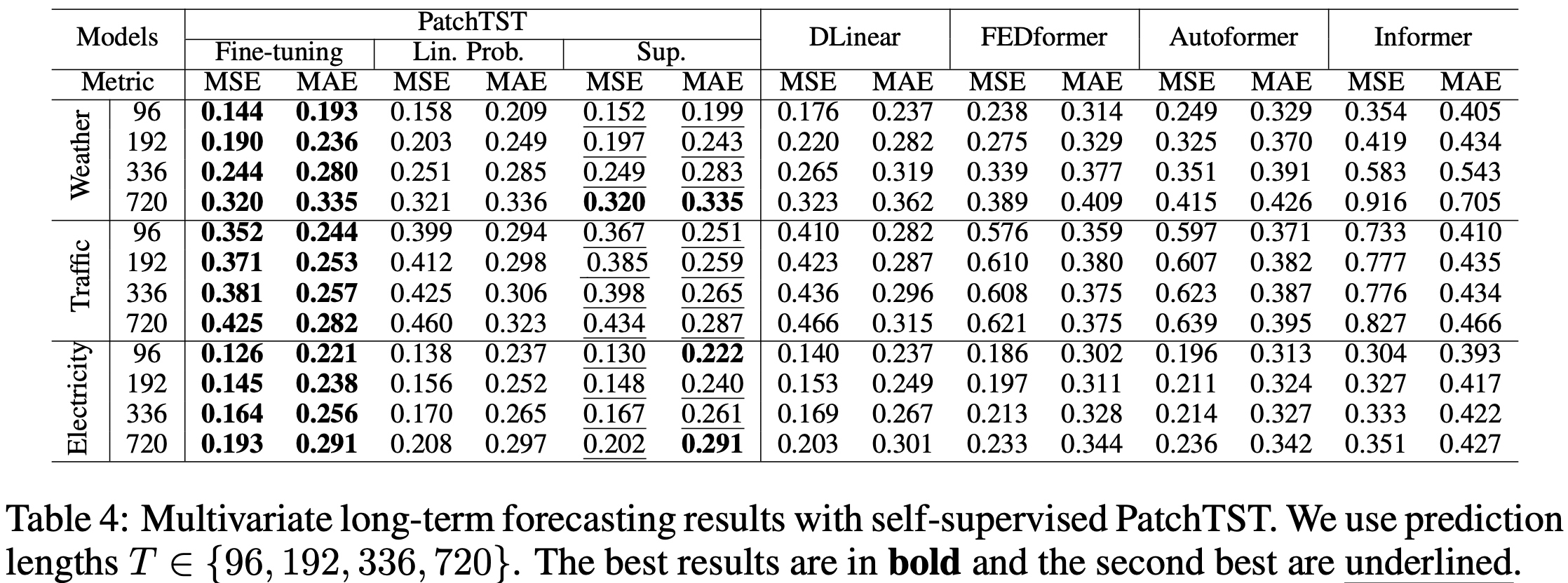
두 결과에서 모두 PatchTST가 좋은 결과를 보여주었다. 그러나, 시계열 데이터 예측에는 MLP, CNN, RNN, LSTM 등 다른 아키텍쳐로 만들어진 모델들이 좋은 성능을 보여주므로 이 모델들과의 비교가 필요해보인다.
4.2 Ablation Study

5. 정리
해당 논문은 제한적인 상황에서의 시계열 예측을 위한 효율적인 모델을 만드는 것을 목표로 한 것으로 보여집니다. 그 이유는 다음과 같습니다:
- Patching을 통해 시/공간 복잡도를 줄이고자 했다.
- Channel-independent model이 데이터가 적은 상황에 더 좋은 성능을 낼 수 있음을 보여주었다.
- (Princeton & IBM reaserch 치고는) 하이엔드급이 아닌 GPU (NVIDIA A40 48GB)를 사용했다.
그러나 그럼에도 여전히 좋은 성능을 보여주며 여러 데이터셋에서 상위 랭크를 기록하고 있습니다. 따라서 컴퓨팅 자원이 부족한 경우에 시계열 예측을 위한 좋은 모델이라고 볼 수 있습니다.



